
一、理论原理
传统文献综述通常用于回顾、讨论已有研究及存在的不足(current gaps)、新研究的原理等,特点是没有对文献如何辨别、选取以及评价的具体方法进行描述。系统性文献综述的特点是研究问题事先确定,全面检索所有相关文献,有明确纳入和排除文献的标准,有批判性分析研究质量的标准,有明确的提炼和综合研究发现的方法(定性或定量)。[1]
1. 文献综述分类
系统综述(systematic review)被定义为“对一个明确表述的问题的证据进行综述,使用系统和明确的方法来识别、选择和批判性评价相关的初步研究,并从综述包括的研究中提取和分析数据。”所用方法必须是可复制和透明的。[2]
元分析(meta-analysis)与元聚合分析(meta-aggregation)都是文献综述的一种方法,都是对相关研究进行分析、评价以及综合的方法。其中,元分析专门用于对定量研究文献中的数据进行统计处理,以探索新的发现。元聚合分析,也称为meta-synthesis,是针对定性研究文献中的数据或主题编码、归类和整合,并给出行动建议。[3]
2. 文献综述操作步骤
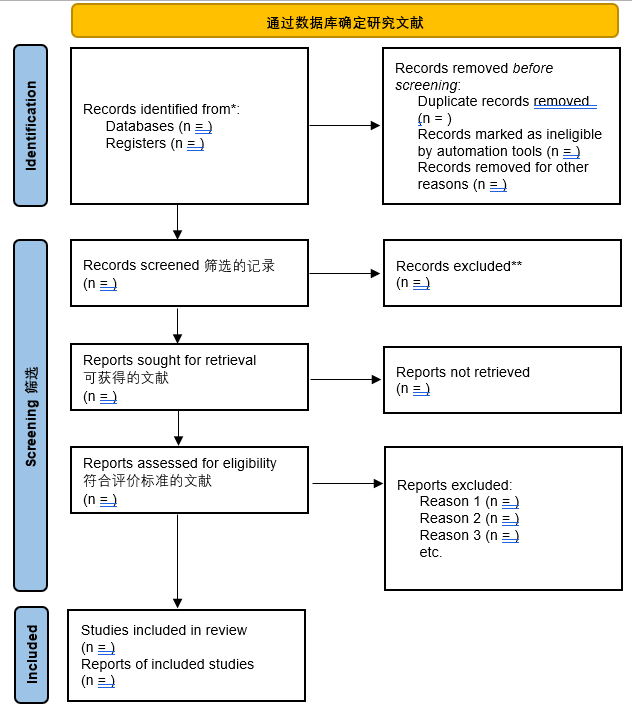
系统性文献综述的7个步骤:[1]
- 组建小组(至少两名评审员,第三名评审员作为仲裁者)
- 提问(定义一个狭窄的问题,可以使用PICO)
- 计划(制定方案、设计方法和策略)
- 检索/筛选(彻底、透明和可重复搜索证据/选择研究)
- 文献管理和报告
- 数据提取/综合相关证据
- 总结、写作和出版
PRISMA网站很重要,有详细的系统综述和元分析的原理声明、操作步骤、流程图等。顶级期刊Computers & Education只接受PRISMA流程的文献综述研究。[4]

二、元分析
元分析(Meta-analysisi)是对有关同一个主题的多项独立的定量研究进行再次分析,进而得出一般性的结论。
(一)元分析的文献编码
收集完文献之后,要逐一检查,从如下几个方面进行编码:【5】
- 有关文献的实质性方面。包括样本来源,人口统计学特征、个人特征,自变量、理论取向、所描述的层次、干预实施的模式等等。
- 量化研究的方法和步骤。包括抽样步骤或方法,调查设计,统计功效,测量的性质,数据分析形式,自变量,实验条件,控制组的性质等。
- 对文献的来源进行描述。
(二)资料的综合
由于研究的目的各不相同,各项研究的指标不尽相同,因此元分析首先要将各项研究的指标转化为统一的指标,即效应量(effect sizes),它是元分析的核心概念。元分析收集的定量信息有很多类,对应每一类也存在不同的效应值。给出各个效应值之后,应该分析其分布,计算其均值,计算置信区间,对同质性进行评价(homogeneity test)。【5】
- 平均效应值。对这些值进行综合加权,计算合并后的平均统计量。
- 计算置信区间。一个平均效应值的置信区间以均值的标准误和z分布的一个临界值为基础的。
- 同质性检验。元分析的前提条件,即多个独立研究之间应该相似。如果各个独立的研究之间具有同质性,便可以将多个统计量进行加权合并;若不一致,可以考虑剔除特大、特小或方向相反的统计量后再综合。如果经过这一步仍然达不到要求,就不能用元分析的方法了。同质性检验的方法有图示法(直方图、茎叶图、散点图等),Q检验。【5】
对于在研究方法存在较大差异的诸多单项研究来说,一个较好的元分析法应将这种差异考虑在内,设置必要的调节变量。另外,当代的元分析法越来越专注于效应值分布的方差,而不是这些分布的均值。也就是说关注的主要问题常常与区分出各项研究结果之间的差异的根源有关,而不是把各个结果聚焦在一起得出一个总的均值。这个关注点针对性质不同的研究结果的子群进行认真的处理,因而较少收到批评。【5】
另外,由于元分析关注的是不同研究结果的聚集和比较,因而有必要保证对这些研究结果的比较是有意义的。这意味着这些结果必须:(1)在概念上具有可比性,即处理的是相同的因子和关系;(2)以相似的统计形式呈现。【5】
[1] Cochrane. Background to Systematic Reviews
[2] 美国Temple大学图书馆网站:What is a Systematic Review? (详细解释了其中的7个步骤).
[3] Florczak K L . (2019). Meta-Aggregation: Just What Is It?. Nursing Science Quarterly, 32(1):11-11.
[4] PRISMA. Preferred Reporting Items for Systematic Reviews and Meta-Analyses (PRISMA)
[5] 马克·W·利普西、戴维·B·威尔逊著,刘军,吴春莺译. 元分析(Meta-analysis)方法应用指导[M]. 重庆:重庆大学出版社出版, 2019: 前言-2。
 【3】
【3】