RQ1:Hedge's g可以用来计算总体效应量,它有什么特点,还有其它方法计算总体效应量吗?
根据统计学意义的不同,元分析中的效应量可以分为三类:(1)差异类(difference-type),(2)相关类(correlation-type),(3)组重叠(group-overlap)[1]。

差异类效应量一般用于实验研究,进行两组均值比较或多组均值比较。Hedge's g属于差异类,当方差同质假设成立时,实验设计条件下所有的组都用来加权计算。
相关类效应量一般用于变量相关的研究中,其大小衡量了两个或多个变量共变的程度,但也可用以差异比较的研究中,所以,相对于差异类效应量,相关类效应量的应用更广泛。
差异类效应量和相关类效应量都假定总体方差同质,当方差异质、总体非正态以及组之间的样本容量不一样时,使用差异类或相关类效应量都不能准确的估计实际的效应量,此时应该使用的是组重叠效应量。
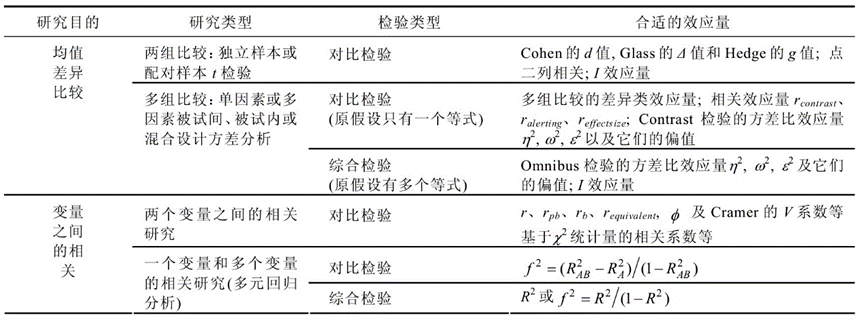
在计算总体效应量时,可以根据研究目的、研究类型、检验类型的不同选择合适的效应量。
RQ2:什么是随机效应模型(random-effects model)?有什么特征和应用条件?
根据各样本效应值是否来自同一总体,元分析提供了两种统计模型假设:固定效应模型和随机效应模型。固定效应模型假设所分析的所有原始研究样本文献中只有一个真实的效应值,所表现出来的差异只是统计抽样误差。随机效应模型则假设各原始研究样本文献中的真实效应值是来自于一个真实效应值分布集合的抽样,因此,真实效应值在研究样本文献间可以有所不同。因此,随机效应模型分析的重要任务是精确地估计这个真实效应值分布[2]。
理论分析表明,各项研究成果所占权重在随机模型中更为均衡一点,相对于固定效应模型而言,在随机效应模型中,大样本研究文献成果会赋予较低的权重,小样本研究文献成果会赋予较高的权重。而且,总效应值的标准误及其置信区间在随机效应模型下会更大更宽一些。
对固定效应模型和随机效应模型的选择取决于样本效应值分布和相关资料误差。
RQ3:Forest plot 和Funnel plot又有什么区别?
Forest plot是发表偏倚逻辑分析的第一步骤,能提供所分析资料的一个视觉印象。在图中,每个研究的效应量及其可信区间以及总的效应量估计值均反映在图上。从Forest plot上能看出总的效应量估计是基于多少研究还是少数几个研究、每个研究的精确程度、纳入分析的研究的效应量分布趋势以及不同研究的效应量之间是否存在显著差别。
Funnel plot是识别发表偏倚的一种普适方法,以样本含量(或效应量标准误)为纵坐标,效应量或效应量对数值为横坐标做散点图。Funnel plot分析基于的假设是效应量估计值的精度随着样本量的增加而增加,反映在图上则为样本量小的研究数越多,精度低,分布在漏斗图的底部,样本量大的研究精度高,分布在漏斗图的顶部。利用Funnel plot可直观反映原始研究的效应量值是否与样本含量有关。如果所有的研究围绕Funnel plot的中心线对称排列,表明没有发表偏倚,如果不对称分布,表示存在发表偏倚[3]。
RQ4:什么是出版偏差(publication bias),有哪些衡量指标?Rosenthal's Fail-safe和 Orwin's Fail-safe 的数量指什么?
出版偏差(publication bias)是指有统计学意义的研究结果比无统计学意义的研究更容易投稿和被发表。对于无统计学意义的研究,研究者可能认为意义不大,不发表或推迟发表;作为杂志编辑则更有可能对这类论文退稿。因为存在发表性偏倚,即使具备周密的检索策略和手段(如与研究者个人联系),也不可能完全地纳入所有相关研究,从而影响元分析结果[4]。
衡量出版偏差的方式包括:①抽屉分析/估计未发表文章量(a file drawer analysis/Failsafe N);②漏斗图(Funnel plot);③Egger's test;④Rank-correlation test;⑤p-uniform's publication bias test/p-curve;⑥TES法(Test of excess significance);⑦Meta-plot。
Rosenthal Nfs是Rosenthal在1979年提出的一个概念,定义为:当Meta分析结果有统计学意义时,为排除可能的发表偏倚,可计算最少需要多少个未发表的研究才能使Meta分析的结论逆转。Orwin’s Nfs是最少需要多少个未发表的研究才能导致总的效应量值在所选择的特定的最小效应量值以下[3]。
RQ5:调节变量分析(Moderator analyses)结果的评判依据是什么?什么是同质性检验(Heterogeneity)?
在元分析中,①面对单一类别调节变量:当其为二分类变量时,其调节分析有两类检验方法,一是Z检验,二是基于Q统计量的χ2检验,两者是等价的。当类别为三分类及其以上时,则是基于Q统计量的χ2检验,与χ2分布下α所对应的临界值进行比较,即可判断出结果的显著性。②面对单一连续型调节变量:有两种处理方法:一是将连续型变量重新分为类别型变量,但分类一定要有认可的心理学标准,结果评判方法与单一类别调节变量相同;二是采用元回归分析,依据调节变量的效应大小服从χ2分布,可判断是否有显著性。若有,表明调节变量对因变量有统计学意义,可以为解释异质性提供依据。③面对多个不同类型的调节变量,则需要用一般多元回归模型来解决[5]。
同质性检验:从实证角度检验每一个研究结果是否可以代表总体效应量的样本估计。
[1]郑昊敏,温忠麟 & 吴艳.(2011).心理学常用效应量的选用与分析. 心理科学进展(12),1868-1878.
[2]崔智敏 & 宁泽逵.(2010).定量化文献综述方法与元分析. 统计与决策(19),166-168. doi:10.13546/j.cnki.tjyjc.2010.19.003.
[3]王珍,张永红 & 徐巧巧.(2009).几种发表性偏倚评估方法介绍. 中国卫生统计(05),539-541.
[4]康德英,洪旗,刘关键,王家良.(2003).Meta分析中发表性偏倚的识别与处理. 中国循证医学杂志(01),45-49.
[5]陈维,黄梅 & 张进辅.(2021).元分析的调节分析与一般调节分析的概念、统计检验及比较.贵州师范大学学报(自然科学版)(05),108-112. doi:10.16614/j.gznuj.zrb.2021.05.018.